This would prove difficult enough for our pre-existing relatively small content base if we relied on our existing technology and largely manual methods. It would've been nearly impossible for our present content base which includes over 500 unique pages of educational resources and more than 4200 figures, diagrams and images. Clearly, new software technology would be required to help us meet these goals.
Therefore, software development and technology became a significant part of the WW2010 project. The following paragraphs describe some of this work further.
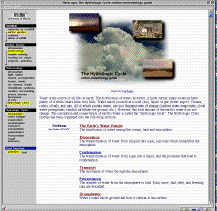
Each page on the WW2010 server is formatted in the same way. On the left of every page is an ever-present vertical gray bar (the navigation bar). The remainder of the page to the right has a white background and is called the content area since it contains the content (text, figures, etc.) of the page. At the top of each page is the page title and optional subtitle and at the bottom is a footer area that contains legal info and credits as well as forward/backward navigation buttons. With few exceptions, each page is formatted very consistently in this manner. (See Fig. 1)
The navigation bar contains a hierarchical series of menus. The menu at the top lists the broadest categories while sub-menus below that list increasingly more specific categories each with the current item highlighted and linked to the next menu below with an arrow. In this way, the user can always see exactly where they are in the server's hierarchy. By clicking on the items at any level the user can jump to other pages or categories. Presently, the worst-case number of clicks required to go between any two arbitrary pages is six, but would typically be less. By following links within the text or by using the forward and backward arrows at the bottom of each page (not shown in figure) to step through a logical sequence of pages, the user can also move around the server. The navigation system updates accordingly.
A special "User Interface" menu is also included. Normally, the navigation menus are presented graphically. If the "text" user interface mode is selected, then they are instead displayed as text-only tables. In this mode, other extraneous graphic elements on the page are removed and any large images, figures, etc. on the page are replaced with descriptive links that include the file size of the graphic and access the graphic only at the user's request. In this way, low bandwidth users can move quickly about the server and only turn on the graphics when needed.
One additional feature to describe here is called a helper page. Throughout the server many key words in the text are hyperlinked. For example, the text might use the word advection in the explanation of another topic. Because this term may be unfamiliar to the reader, it is hyperlinked to its definition. Because we have an extensive discussion concerning various types of advection in the Air Masses and Fronts module, we could send the user there if they clicked advection. However, there is a danger that they could easily get lost or sidetracked in the new location and never get back to the original text that had used advection to describe something else.
Instead we take them to a helper page which describes just that term in a more concise format. The normal navigation menus disappear and are replaced with a very simple one that either takes the user back to the original text or gives them the option of going into more detail on the term. (See Fig. 2)
Despite the complexity of maintaining all of these features just described, the page author only needs to concern themselves with the content area of the page and the placement of the page within the server's hierarchy. The details of page layout, navigation menu generation, graphics/text display modes and helper page management are all handled automatically as described in the next section.

In the WW2010 design, the content of each web page on the server undergoes several processing steps before it reaches the user's browser (as compared to the normal way of doing things in which a HTML file is simply read from the server's disk and delivered verbatim to the requesting browser). These steps involve both preprocessing a source form of the page content once during development and post processing the resulting content data again on the fly each time a page is requested.
These ATML files (as well as any GIF of other associated files) are placed into normal directories on the UNIX server. Each directory corresponds to exactly one navigation menu (sub-category). The relationship of these directories to each other is what defines the server's hierarchical organization. Sub-directories correspond to sub-menus of a higher level menu. Each directory has a special file called an AT file which is used to define the formal name that appears in the black bar of the navigation menus and to list the menu's items (directories for sub-menus and ATML files for pages) in the order they should appear.
1) The current directory's AT file is parsed and the directory is scanned for new/changed ATML files or sub-directories. AutoTree is similar to the UNIX make utility in that it automatically figures out what needs to be done and does the minimum amount of work each time to update the server.
2) It parses the contents of the ATML files extracting the metadata and content. The format of the file is checked for errors such as invalid HTML or links or image tags that point to non-existent files.
3) Helper pages are extracted. A helper page is simply a subset of another more detailed page. After writing the detailed page, the author simply delimits portions of it to be used as a helper page by surrounding it with <WWHLPR ident="x"> </WWHLPR> tags. The stuff in between these tags becomes helper page "x" and can be linked to from elsewhere with the notation <A hlpr="x"> link </A>.
4) All the data gathered in the steps above is then stored in an SQL database. This database is used to later access this information without having to rescan the files and directories.
5) Both the text and graphics version of the navigation menu for that subsection are generated. This means generating HTML tables for the text version and a GIF file for the graphics version, plus the necessary HTML to imagemap it.
6) A processed version of the page is written out as a RXML file which includes both the modified page content and added code for the menus, as well as other elements to be processed by the server at the time of the page request. This is described below. AutoTree is now done with its business and leaves these resulting files for request-time processing by the server.
Again, while this sounds very involved, it is fairly transparent to the page author. As long as they understand the simple rules of constructing ATML files and AT directories and remember to run a single letter command to launch AutoTree in each directory where a change is made, everything else is taken care of for them in a matter of a few seconds. We have taught over a dozen students and staff members here with minimal pre-existing HTML knowledge to be quite proficient with this system.
One such powerful extension that it provides is the <IF somecondition> </IF> tagset. You can surround a portion of your HTML document with these tags and that portion will only be sent to the browser when somecondition is true. By using this, one can dynamically change the contents of a page each time it is accessed. After the server processes the <IF> or other RXML tags, it removes them from the output. The result is that only pure HTML arrives at the browser.
In addition to the <IF> tagset, it offers a number of other useful ones. If those are insufficient, one can define their own tags and extend Roxen's abilities to process them by writing your own modules for Roxen in their unique Pike programming language. We did just that for WW2010.
Recall that AutoTree generates RXML files. One of the things it includes in that RXML file is a special tagset that surrounds the rest of the content. We defined this tagset in Roxen to take the content and format it according to a global template. This global template is responsible for setting up the tables that define the areas on the page, setting up the gray menubar, adding the page title and footer and inserting the page contents into this.
This global layout template is what keeps the format consistent between all pages. If a server-wide change in formatting is desired, only the global layout template needs to be modified and the every page instantly looks different.
You may wonder why the application of the template is done at request time rather than done once in advance by AutoTree. This is because it allows us to employ lots of <IF> tags in the template to make adjustments for each request.
One of the things that we do is to tailor the layout in several small ways to look best depending on the browser the page is being access with at a given time. We, for example, increase the width of the gray navigation bar when UNIX versions of Netscape prior to 4.0 are accessing pages since it formats them somewhat differently than the PC and Mac versions do. The graphics and text versions of the pages are handled in a similar fashion. We can say if Text mode show this else show that (if graphics mode).
This posed a special challenge since none of the request time processing is available on the CD-ROM which must contain only straight HTML files.
It was accomplished by extensively modifying off-the-shelf web site mirroring software. This software basically connects to the server and recursively requests every page on the server and saves it to local disk. It goes to great lengths to adjust all the links to be completely relative and to convert the file/path names to be DOS compatible and adjust every link accordingly. This proved to be non-trivial. Additional <IF> tags are activated to change portions of the server text to read differently on the CD-ROM version.
Because the contents of the entire server may be passed through a program and the program more or less understands what it is looking at (at least symbolically) you can easily do all sorts of things. For example, for the CD-ROM version, we decided that wherever there is a link to an on-line site that would take the user beyond the bounds of the CD-ROM, we wanted to warn them by placing a tiny lightning bolt icon in front of the link. Since there are about 350 such links (3%), this would be prohibitive to do by hand. However with our system, it was accomplished in less than five minutes by adding a few lines of code to AutoTree to detect an external link and insert a image tag before it.
Also, because the contents of the server are stored in an SQL database bu AutoTree, the future possibilities for doing intelligent searches, indexes, etc. are abundant.
Additional benefits include extensive error checking (bad HTML, broken links, etc.). and the ability to use a single source file for both graphics, text and CD-ROM versions as well as for helper pages. A future version will include built in version control for the content source files.
Plutchak, S. et al., 1998: Weather World 2010: A Customizable, User-oriented WWW Site. Proceedings for the 14th IIPS Symposium. Pheonix, AZ, American Meteorological Society
Plutchak, et al., 1998: Java on the World Wide Web and Beyond. Proceedings of the 14th IIPS Symposium. Pheonix, AZ, American Meteorlogical Society.
* Corresponding Author Address:
David Wojtowicz, Dept of Atmospheric Sciences
University of Illinois at Urbana-Champaign,
105 S. Gregory St., Urbana, IL 61821
e-mail: davidw@uiuc.edu